
 Tweet
Tweet
Computer-aided translation (CAT)
The term Computer-aided Translation (CAT) refers to a translation modus operandi in which human translation (HT) is aided by computer applications. A competing term, Machine-aided Translation (MAT), is also in use, particularly within the software community involved in developing CAT applications. A key characteristic of CAT is that a human translator takes control of the translation process and technology is used to facilitate, rather than replace, HT.
Technology-based solutions to translation needs are a natural consequence of the shortened timeframe available for translation and increasing budgetary constraints resulting from globalization, as well as the progressive digitization of source content. CAT has become the predominant mode of translation in scientific and technical translation and localization, where technology is employed to increase productivity and cost-effectiveness as well as to improve quality. The technology applications in CAT – commonly referred to as CAT tools – include ‘any type of computerized tool that translators use to help them do their job’. Thus, CAT tools range from general-purpose applications such as word-processors, optical character recognition (OCR) software, Internet search engines, etc., to more translation-oriented tools such as multilingual electronic dictionaries, corpus analysis tools, terminology extraction and terminology management systems. Having emerged as one of the earliest translation technologies in the 1970s, translation memory (TM) was commercialized in the mid-1990s, becoming the main CAT tool since the late 1990s.
Translation Memory technology
TM allows the translator to store translations in a database and ‘recycle’ them in a new translation by automatically retrieving matched segments (usually sentences) for re-use. The TM database consists of source text and target text segment pairs which form so-called translation units (TUs). After dividing a new ST into segments, the system compares each successive ST segment against the ST segments stored in the translation database. When a new ST segment matches an ST segment in the database, the relevant TU is retrieved. These matches are classified as ‘exact matches’, ‘full matches’ and ‘fuzzy matches’. An exact match means that the ST segment currently being translated is identical, including formatting style, to a segment stored in the memory. A full match means that the ST segment matches one stored in the memory with differences only in ‘variable’ elements such as numbers, dates, time, etc. A fuzzy match is one where the ST segment is similar to a segment in the memory, which can be re-used with some editing. The fuzzy matching mechanism uses character-based similarity metrics where resemblance of all characters in a segment, including punctuation, is checked.
TM technology relies on text segmentation and alignment. Segmentation is the process of splitting a text into smaller units, such as words or sentences. Most TM systems use the sentence as the main unit, but also recognize as segments other common stand-alone units such as headings, lists, table cells or bullet points. The user is normally able to override the default segmentation rules by setting user-specific rules and also by shrinking or extending the proposed segmentation in interactive mode. In Latin-based scripts, where white space or a punctuation mark generally indicate a word boundary, segmentation is relatively straightforward. This is not the case in non-segmented languages such as Chinese, Japanese and Thai, which do not use any delimiters between words. A non-segmented source language can therefore affect TM performance, even though TM systems are designed to be largely language independent. On the basis of segmentation, the process of alignment explicitly links corresponding segments in the source and target texts to make up TUs. Alignment algorithms are usually based on ‘anchor points’ such as punctuation, numbers, formatting, names and dates, in addition to the length of a segment as a measure for correspondence. When a memory is created in interactive mode, alignment is verified by the translator. However, when automatic alignment is used to create memories retrospectively from past translations, known as ‘legacy data’, misalignments may occur. Misalignments may be caused by instances of asymmetry between the source and target texts, for example when one ST segment is not translated into one TT segment, or when the order of sentences is changed in the TT. These problems may be exacerbated in translations between less closely-related language pairs.
In a relatively short time-span, TM technology has evolved from a first-generation ‘sentence-based memory’, only able to search exact matches on the level of the full sentence, to a second generation where fuzzy matches can also be retrieved. A third generation of TM technology is now emerging where repetitions below sentence level – sub-sentential matches – are exploited. Translation researchers have discussed the disadvantages of using the sentence as the key processing unit from the viewpoint of translator productivity as well as from the perspective of the translator’s cognitive process. More efficient approaches to identifying useful matches for the translator have been explored, but an ideal translation unit which optimizes precision and recall of matches, while facilitating but not interfering with the human translator’s cognitive process, is still to be identified.
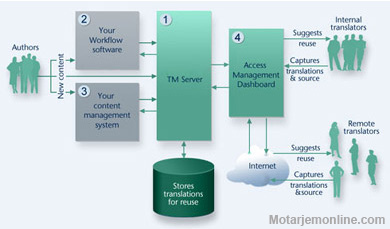
Translation workflow in CAT
TM systems are usually provided in the form of a translator’s ‘workbench’, where different tools such as terminology management systems and concordancers are integrated into the translation environment to facilitate a streamlined workflow. A distributed translation mode is supported in most TM products to allow a translation job to be divided and allocated to a number of translators in separate physical locations connected via an electronic network. This client–server architecture enables a team of translators to share simultaneously the same TM and a termbase on a network, irrespective of their physical locations. Such a distributed workflow is usually further supported by translation management tools to monitor and keep track of the progress of several concurrent translation projects. The need to be able to exchange linguistic data between different proprietary TM systems has led to the development of standards such as translation memory exchange (TMX), termbase exchange (TBX) and, more recently, segmentation rules exchange (SRX) formats. The localization industry has led this initiative through the OSCAR (Open Standards for Container/Content Allowing Reuse)group, part of the Localization Industry Standards Association (LISA). The main advantage of these standards is the freedom of using different CAT tools for different projects, as required by each client or agency, while still being able to exploit the previously accumulated data in any other system.
CAT tools such as TM have introduced new processes in the translation workflow. For example, a text destined to be translated with TM is likely to undergo a pre-analysis process. The use of the analysis tool, which is usually a component of the TM system, provides information on repetitions within a new ST and matches against an existing TM database. The statistics gained from these processes have various implications, including deductions on translation fees for the segments with existing matches. TM has also introduced a ‘pre-translation’ process where TM is used in a non-interactive context prior to beginning the actual translation process. The pre-translation function compares the new ST against the contents of the TM database and automatically replaces any ST matches with the corresponding target-language segments, thus producing a hybrid text, partly in the source language and partly in the target language. This function enables clients to avoid giving the translator direct access to their TM database as well as overcoming the issue of data format incompatibility between different TM products. However, the resulting text poses a new challenge to the translator, who not only has to translate the source language fragments but also to verify and transform into an acceptable translation the target language fragments which may only partially correspond to given ST segments. Wallis (2006) suggests that the use of the TM pre-translation function could have a negative impact in terms of translators’ job satisfaction as well as translation quality.
Widespread impact of TM
The benefit of re-using previous human translations for the same or similar segments has been largely accepted in the commercial translation world. Accordingly, it has become common practice to obtain discounts in translation fees if there are pre-existing TM matches. As a result, TM has occasionally created unrealistic expectations that it instantly provides substantial cost savings without any negative consequences for the quality of the translation. Even when there are exact matches, the translator still needs to consider the text as a whole, and in the light of the new context in which the matched segments are to be inserted. It is possible for TM to create a ‘sentence salad’ effect when sentences are drawn (without adequate contextual information) from various translation memories created by different translators with different styles. A related problem, described as ‘peep-hole translations’, concerns the cohesion and readability of the translation, which can be compromised for the sake of facilitating TM – for example, when translators avoid the use of anaphoric and cataphoric references, opting instead for lexical repetitions that can yield more exact or full matches. A study on consistency and variation in technical translation suggests that while the consistency facilitated by TM is in keeping with the general aim of technical translation, it is not always welcomed by some translators when the same segment appears in different functional contexts. Industry sources have also reported anecdotal evidence of TM’s negative impact on the development of translation competence, although this needs to be substantiated by indepth empirical studies. The cost of the software and the steep learning curve are also seen as negative aspects of TM.
Another controversial issue concerns the ownership of the content of a translation memory, which can be a commercially valuable asset. The ethical question of whether or not the particular memory data belong to the commissioner of the job or to the translator escapes the parameters of conventional copyright agreements. The use of the pre-translation
function mentioned above is generally motivated by the client’s desire to maintain exclusive access to their TM content. At the same time, various initiatives are now emerging to share TM data on a cooperative basis, as proposed by the Translation Automation User Society (TAUS), or a commercial basis, such as TM Marketplace licences, with far reaching implications for the scope of translation recycling.
Future of CAT
CAT is likely to be enhanced by the use of a wide range of technology components which have not been developed specifically with translation tasks in mind. For example, speech recognition systems are becoming a popular CAT tool among translators, including their integration into TM systems. In the area of audiovisual translation, speech recognition technology is being applied to the production of intralingual subtitles for live TV programmes in a mode called ‘re-speaking’, where subtitles are generated in real time by the subtitler dictating, instead of typing, subtitles to the computer. In terms of the use of Internet-related technology, Bey et al.(2006) have proposed to design and develop an online CAT environment by exploiting Web-based collaborative authoring platforms such as Wiki with a view to facilitating translation work by volunteer translators who collaborate online.
The increasing availability of corpora is also likely to impact the future of CAT. A feasibility study on the application of Example-based MachineTranslation (EBMT) to Aaudiovisual translation, for example, was inspired by the potential re-usability of prior translations of subtitles which are becoming increasingly available in electronic form. In parallel with further automation involving the integration of TM and machine translation into the translation workflow, fine-tuning of TM technology continues to focus on how to assist the human translator. The enhancement of CAT applications is likely to benefit from translator-focused investigations, such as empirical process-oriented translation research. Dragsted (2004, 2006), for example, has highlighted a discrepancy between technology-imposed segmentation of TM and the cognitive segmentation inherent to the human translation process, and O’Brien (2006) has looked at differences in translators’ cognitive loads when dealing with different types of TM matches. Market demands will continue to drive applied research on CAT but, as highlighted in recent studies eliciting users’ views on TM systems, involvement of the professional community of translators in the research and development of CAT tools is crucial in shedding light on the practical implications of the use of technology in this field.
Minako O’Hagan
Source: Routledge Encyclopedia of Translation Studies
The term Computer-aided Translation (CAT) refers to a translation modus operandi in which human translation (HT) is aided by computer applications. A competing term, Machine-aided Translation (MAT), is also in use, particularly within the software community involved in developing CAT applications. A key characteristic of CAT is that a human translator takes control of the translation process and technology is used to facilitate, rather than replace, HT.
Technology-based solutions to translation needs are a natural consequence of the shortened timeframe available for translation and increasing budgetary constraints resulting from globalization, as well as the progressive digitization of source content. CAT has become the predominant mode of translation in scientific and technical translation and localization, where technology is employed to increase productivity and cost-effectiveness as well as to improve quality. The technology applications in CAT – commonly referred to as CAT tools – include ‘any type of computerized tool that translators use to help them do their job’. Thus, CAT tools range from general-purpose applications such as word-processors, optical character recognition (OCR) software, Internet search engines, etc., to more translation-oriented tools such as multilingual electronic dictionaries, corpus analysis tools, terminology extraction and terminology management systems. Having emerged as one of the earliest translation technologies in the 1970s, translation memory (TM) was commercialized in the mid-1990s, becoming the main CAT tool since the late 1990s.
Translation Memory technology
TM allows the translator to store translations in a database and ‘recycle’ them in a new translation by automatically retrieving matched segments (usually sentences) for re-use. The TM database consists of source text and target text segment pairs which form so-called translation units (TUs). After dividing a new ST into segments, the system compares each successive ST segment against the ST segments stored in the translation database. When a new ST segment matches an ST segment in the database, the relevant TU is retrieved. These matches are classified as ‘exact matches’, ‘full matches’ and ‘fuzzy matches’. An exact match means that the ST segment currently being translated is identical, including formatting style, to a segment stored in the memory. A full match means that the ST segment matches one stored in the memory with differences only in ‘variable’ elements such as numbers, dates, time, etc. A fuzzy match is one where the ST segment is similar to a segment in the memory, which can be re-used with some editing. The fuzzy matching mechanism uses character-based similarity metrics where resemblance of all characters in a segment, including punctuation, is checked.
TM technology relies on text segmentation and alignment. Segmentation is the process of splitting a text into smaller units, such as words or sentences. Most TM systems use the sentence as the main unit, but also recognize as segments other common stand-alone units such as headings, lists, table cells or bullet points. The user is normally able to override the default segmentation rules by setting user-specific rules and also by shrinking or extending the proposed segmentation in interactive mode. In Latin-based scripts, where white space or a punctuation mark generally indicate a word boundary, segmentation is relatively straightforward. This is not the case in non-segmented languages such as Chinese, Japanese and Thai, which do not use any delimiters between words. A non-segmented source language can therefore affect TM performance, even though TM systems are designed to be largely language independent. On the basis of segmentation, the process of alignment explicitly links corresponding segments in the source and target texts to make up TUs. Alignment algorithms are usually based on ‘anchor points’ such as punctuation, numbers, formatting, names and dates, in addition to the length of a segment as a measure for correspondence. When a memory is created in interactive mode, alignment is verified by the translator. However, when automatic alignment is used to create memories retrospectively from past translations, known as ‘legacy data’, misalignments may occur. Misalignments may be caused by instances of asymmetry between the source and target texts, for example when one ST segment is not translated into one TT segment, or when the order of sentences is changed in the TT. These problems may be exacerbated in translations between less closely-related language pairs.
In a relatively short time-span, TM technology has evolved from a first-generation ‘sentence-based memory’, only able to search exact matches on the level of the full sentence, to a second generation where fuzzy matches can also be retrieved. A third generation of TM technology is now emerging where repetitions below sentence level – sub-sentential matches – are exploited. Translation researchers have discussed the disadvantages of using the sentence as the key processing unit from the viewpoint of translator productivity as well as from the perspective of the translator’s cognitive process. More efficient approaches to identifying useful matches for the translator have been explored, but an ideal translation unit which optimizes precision and recall of matches, while facilitating but not interfering with the human translator’s cognitive process, is still to be identified.
Translation workflow in CAT
TM systems are usually provided in the form of a translator’s ‘workbench’, where different tools such as terminology management systems and concordancers are integrated into the translation environment to facilitate a streamlined workflow. A distributed translation mode is supported in most TM products to allow a translation job to be divided and allocated to a number of translators in separate physical locations connected via an electronic network. This client–server architecture enables a team of translators to share simultaneously the same TM and a termbase on a network, irrespective of their physical locations. Such a distributed workflow is usually further supported by translation management tools to monitor and keep track of the progress of several concurrent translation projects. The need to be able to exchange linguistic data between different proprietary TM systems has led to the development of standards such as translation memory exchange (TMX), termbase exchange (TBX) and, more recently, segmentation rules exchange (SRX) formats. The localization industry has led this initiative through the OSCAR (Open Standards for Container/Content Allowing Reuse)group, part of the Localization Industry Standards Association (LISA). The main advantage of these standards is the freedom of using different CAT tools for different projects, as required by each client or agency, while still being able to exploit the previously accumulated data in any other system.
CAT tools such as TM have introduced new processes in the translation workflow. For example, a text destined to be translated with TM is likely to undergo a pre-analysis process. The use of the analysis tool, which is usually a component of the TM system, provides information on repetitions within a new ST and matches against an existing TM database. The statistics gained from these processes have various implications, including deductions on translation fees for the segments with existing matches. TM has also introduced a ‘pre-translation’ process where TM is used in a non-interactive context prior to beginning the actual translation process. The pre-translation function compares the new ST against the contents of the TM database and automatically replaces any ST matches with the corresponding target-language segments, thus producing a hybrid text, partly in the source language and partly in the target language. This function enables clients to avoid giving the translator direct access to their TM database as well as overcoming the issue of data format incompatibility between different TM products. However, the resulting text poses a new challenge to the translator, who not only has to translate the source language fragments but also to verify and transform into an acceptable translation the target language fragments which may only partially correspond to given ST segments. Wallis (2006) suggests that the use of the TM pre-translation function could have a negative impact in terms of translators’ job satisfaction as well as translation quality.
Widespread impact of TM
The benefit of re-using previous human translations for the same or similar segments has been largely accepted in the commercial translation world. Accordingly, it has become common practice to obtain discounts in translation fees if there are pre-existing TM matches. As a result, TM has occasionally created unrealistic expectations that it instantly provides substantial cost savings without any negative consequences for the quality of the translation. Even when there are exact matches, the translator still needs to consider the text as a whole, and in the light of the new context in which the matched segments are to be inserted. It is possible for TM to create a ‘sentence salad’ effect when sentences are drawn (without adequate contextual information) from various translation memories created by different translators with different styles. A related problem, described as ‘peep-hole translations’, concerns the cohesion and readability of the translation, which can be compromised for the sake of facilitating TM – for example, when translators avoid the use of anaphoric and cataphoric references, opting instead for lexical repetitions that can yield more exact or full matches. A study on consistency and variation in technical translation suggests that while the consistency facilitated by TM is in keeping with the general aim of technical translation, it is not always welcomed by some translators when the same segment appears in different functional contexts. Industry sources have also reported anecdotal evidence of TM’s negative impact on the development of translation competence, although this needs to be substantiated by indepth empirical studies. The cost of the software and the steep learning curve are also seen as negative aspects of TM.
Another controversial issue concerns the ownership of the content of a translation memory, which can be a commercially valuable asset. The ethical question of whether or not the particular memory data belong to the commissioner of the job or to the translator escapes the parameters of conventional copyright agreements. The use of the pre-translation
function mentioned above is generally motivated by the client’s desire to maintain exclusive access to their TM content. At the same time, various initiatives are now emerging to share TM data on a cooperative basis, as proposed by the Translation Automation User Society (TAUS), or a commercial basis, such as TM Marketplace licences, with far reaching implications for the scope of translation recycling.
Future of CAT
CAT is likely to be enhanced by the use of a wide range of technology components which have not been developed specifically with translation tasks in mind. For example, speech recognition systems are becoming a popular CAT tool among translators, including their integration into TM systems. In the area of audiovisual translation, speech recognition technology is being applied to the production of intralingual subtitles for live TV programmes in a mode called ‘re-speaking’, where subtitles are generated in real time by the subtitler dictating, instead of typing, subtitles to the computer. In terms of the use of Internet-related technology, Bey et al.(2006) have proposed to design and develop an online CAT environment by exploiting Web-based collaborative authoring platforms such as Wiki with a view to facilitating translation work by volunteer translators who collaborate online.
The increasing availability of corpora is also likely to impact the future of CAT. A feasibility study on the application of Example-based MachineTranslation (EBMT) to Aaudiovisual translation, for example, was inspired by the potential re-usability of prior translations of subtitles which are becoming increasingly available in electronic form. In parallel with further automation involving the integration of TM and machine translation into the translation workflow, fine-tuning of TM technology continues to focus on how to assist the human translator. The enhancement of CAT applications is likely to benefit from translator-focused investigations, such as empirical process-oriented translation research. Dragsted (2004, 2006), for example, has highlighted a discrepancy between technology-imposed segmentation of TM and the cognitive segmentation inherent to the human translation process, and O’Brien (2006) has looked at differences in translators’ cognitive loads when dealing with different types of TM matches. Market demands will continue to drive applied research on CAT but, as highlighted in recent studies eliciting users’ views on TM systems, involvement of the professional community of translators in the research and development of CAT tools is crucial in shedding light on the practical implications of the use of technology in this field.
Minako O’Hagan
Source: Routledge Encyclopedia of Translation Studies